RAG vs Vectorless RAG: How AI Systems Retrieve Knowledge
How AI finds answers — and why the next generation is rethinking the approach.
Introduction
LLMs are powerful, but they only know what they were trained on — once training ends, new documents, company updates, and recently uploaded PDFs are invisible to them. RAG solves this.
Retrieval-Augmented Generation (RAG) lets the AI search for relevant information before answering. It uses what it finds to write accurate, grounded responses — no retraining required.
💡 In short: RAG = Search first, then generate.
What is RAG?
RAG makes AI "up-to-date" without retraining it constantly. It works in five steps:
1. Indexing: Prepare Your Documents
All documents (PDFs, web pages, text files) are organised into a searchable index — like building a card catalogue in a library. It happens once upfront and updates whenever new documents arrive.
2. Chunking: Split Documents into Pieces
LLMs can only process a limited amount of text at once. So documents are split into chunks — paragraphs or sections — to fit the AI's context window.
- Too small → loses surrounding context
- Too large → wastes the AI's limited memory
3. Embeddings: Turn Text into Numbers
To find meaning, not just keywords, each chunk is converted into a vector — a list of numbers that represents its meaning. Similar concepts produce similar vectors, even when the words are completely different.
Example: "The cat sat on the mat" and "A feline rested on the rug" → nearly identical vectors.
4. Vector Database: Store the Meaning
Vectors are stored in a vector database (Pinecone, Weaviate, Qdrant, FAISS) that enables fast semantic search across thousands — or millions — of chunks.
5. Query Time: Answering Questions
- User asks a question
- Question is converted into a vector
- Semantic search finds the top-k most similar chunks
- Chunks + question are combined into a prompt
- LLM generates a grounded answer
✅ Works well for many applications — but it has real limitations.
Problems with Traditional RAG
The entire RAG pipeline is only as good as its weakest link — retrieval. Here's where it breaks down:
- Chunks lose context — fragments miss the surrounding meaning that gives them significance
- Semantic search isn't perfect — embeddings can miss relevant sections, especially in specialised domains
- Information spans multiple chunks — answers often need several sections combined, but RAG treats each chunk independently
- Chunking is tricky — too big, too small, or overlapping chunks all introduce errors
- Vector databases need maintenance — updating, deleting, and re-indexing adds operational complexity over time
- Confident mistakes — AI writes fluent, authoritative answers even when the retrieved chunks are slightly off-topic
"The weakness of RAG is not the generation — it is the retrieval. If the right information was never found, the best AI in the world cannot save you."
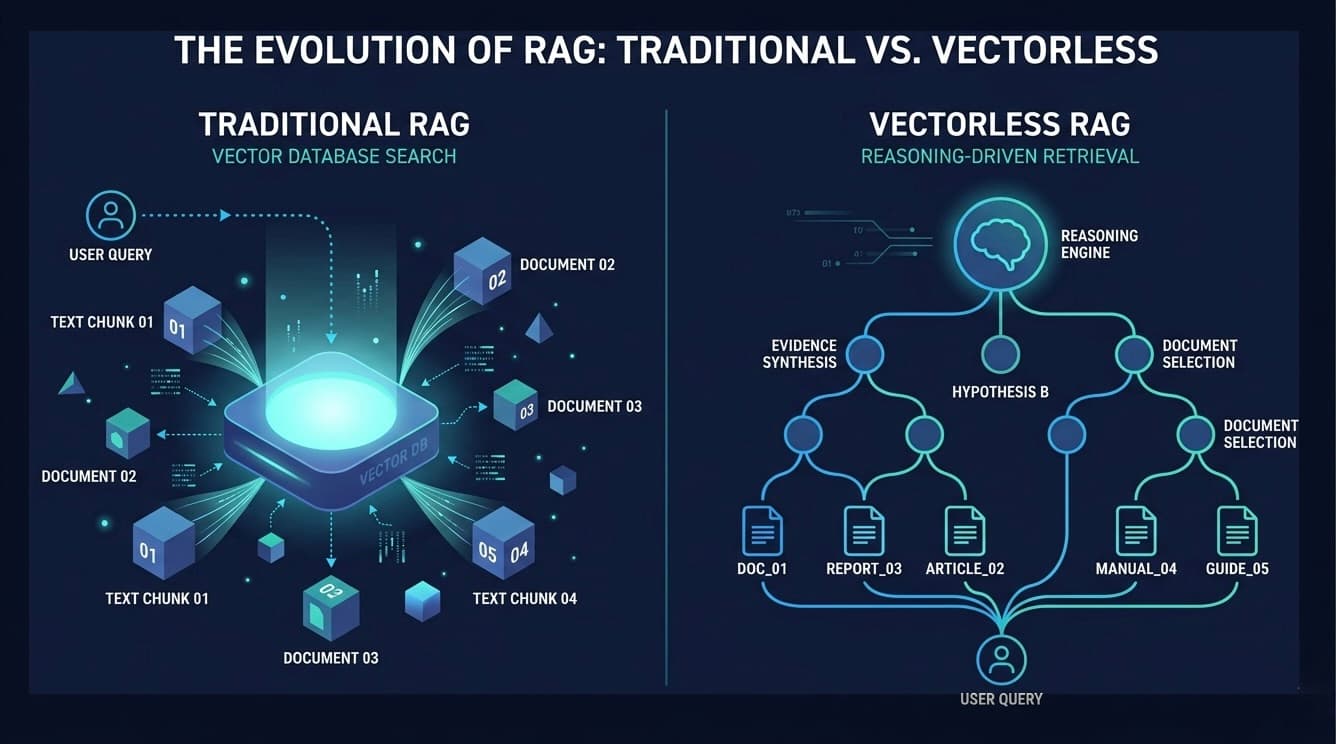
Vectorless RAG: A Different Approach
Vectorless RAG skips vectors entirely. Instead of searching by similarity, it reasons through documents to find answers — like a detective working a case, not a search engine matching keywords.
💡 Core idea: Break the question into sub-questions, navigate to the exact document sections, read them in full, then combine everything into one complete answer.
How It Works
Think of how a doctor diagnoses a patient:
Fever → infection? → what type? → check bloodwork → treat accordingly
Each step guides the next. Vectorless RAG applies this same logic to documents:
Question: What is our employee leave policy?
├── Sick days? → HR Manual, Section 3.2
├── Annual leave? → HR Manual, Section 4.1
└── Approval process? → Policy Doc, Approval Workflow
↓
Read each section in full
↓
Synthesise one complete, context-rich answer
After reading each section in full, the AI combines the answers into one complete, context-rich response — no guessing from fragments.
No embeddings. No vector database. The "index" is simply a clear, hierarchical map of your documents — easy to read, easy to update.
✅ Accurate, context-rich, low maintenance ⚠️ Works best with well-structured documents
RAG vs Vectorless RAG: At a Glance
| Factor | Traditional RAG | Vectorless RAG |
|---|---|---|
| Speed | ✅ Fast (1–3 sec) | ⚠️ Slower (10–30 sec) |
| Accuracy | ⚠️ Moderate | ✅ High |
| Infrastructure | ❌ Complex (vector DB) | ✅ Simple |
| Context quality | ❌ Fragmented chunks | ✅ Full sections |
| Document types | ✅ Any format | ⚠️ Structured docs work best |
| Multi-step reasoning | ❌ Not supported | ✅ Built-in |
Rule of Thumb
- Fast & large-scale? → Traditional RAG
- Accurate & structured? → Vectorless RAG
A slightly slower, accurate answer beats a fast, wrong one — especially in legal, medical, compliance, or technical domains.
Conclusion
RAG opened the door for AI to answer questions about new information. But chunking and vector search create real challenges that limit accuracy in high-stakes situations.
Vectorless RAG bets on reasoning over retrieval — and for structured documents, that bet pays off. It delivers full-context answers with simpler infrastructure and less ongoing maintenance.
The future of AI retrieval may not be in bigger vector databases — it may be in smarter navigation and reasoning.
Found this helpful? Share it with someone building AI systems. Questions or thoughts? Drop a comment below.