SQL or NoSQL? Wrong Question. Here's the Right One.
Series: Backend Engineering Fundamentals · Post 04 of 07 Level: Intermediate · Read time: ~9 min
Every few years the industry declares SQL dead, or NoSQL dead, or NewSQL the future. Meanwhile, production systems quietly keep running on PostgreSQL, with a Redis cache, a MongoDB collection for one specific use case, and an Elasticsearch index for search.
The SQL vs NoSQL debate is the wrong frame. The right question is: what are your data access patterns, consistency requirements, and team capabilities?
Answer those, and the database choice usually becomes obvious.
What SQL Actually Gives You (That's Often Taken for Granted)
Relational databases aren't just "tables with foreign keys." The guarantees they provide are hard to replicate:
ACID Transactions
BEGIN;
UPDATE accounts SET balance = balance - 500 WHERE id = 'alice';
UPDATE accounts SET balance = balance + 500 WHERE id = 'bob';
COMMIT;
-- Either both updates happen, or neither does. No partial state.
You don't appreciate ACID until you've debugged a distributed system where you transferred $500, debited Alice, and then the network failed before crediting Bob.
Joins — Relationship Integrity Without Application Logic
SELECT o.id, o.total, u.name, u.email
FROM orders o
JOIN users u ON o.user_id = u.id
WHERE o.status = 'pending'
AND o.created_at > NOW() - INTERVAL '24 hours';
In a document database, this query becomes application code — multiple fetches, assembled in memory, with no guarantee of consistency.
Schema Enforcement The database rejects data that doesn't fit the schema. This feels restrictive early in development; it becomes invaluable when your system is running 24/7 and a bug tries to write malformed data.
The CAP Theorem — A Useful Mental Model
Distributed systems can guarantee at most two of three properties:
Consistency
(every read returns
the latest write)
/\
/ \
/ \
/ CP \
/ \
/----AP----|
/ \
Availability Partition
(every request Tolerance
gets a response) (system works
despite network
failures)
CP systems (Consistency + Partition Tolerance): Choose correctness over availability. HBase, MongoDB (with certain write concerns), etcd.
AP systems (Availability + Partition Tolerance): Choose availability over strict consistency. Cassandra, CouchDB, DynamoDB (by default).
CA systems: Only possible without network partitions — i.e., single-node systems or systems within a trusted network. Most traditional relational databases in non-distributed setups.
⚠️ In practice, network partitions always can happen. The real choice is between consistency and availability when a partition occurs. Choose based on your domain: banking needs consistency; social media can tolerate eventual consistency.
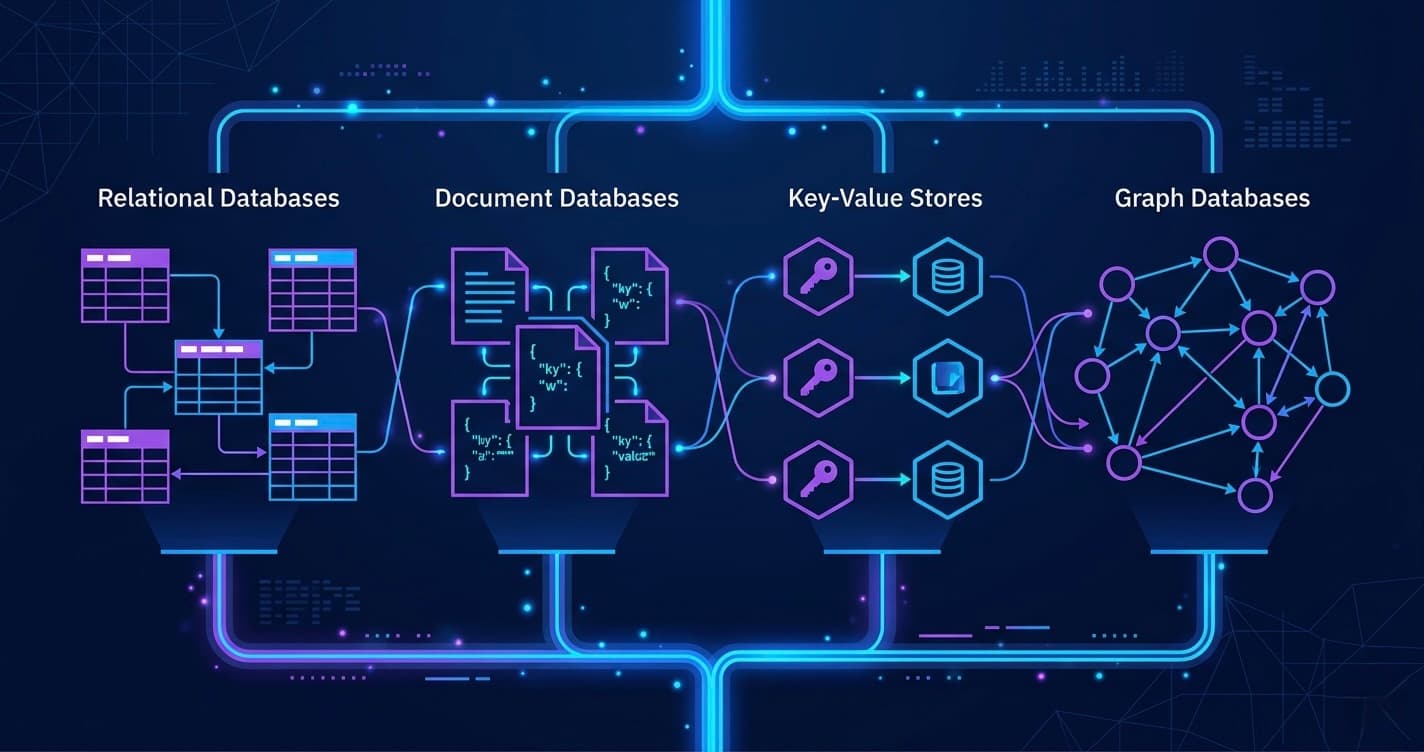
NoSQL Data Models — Picking the Right Tool
"NoSQL" is not one thing. There are four fundamentally different data models:
1. Document Stores (MongoDB, Firestore, CouchDB)
Store data as JSON/BSON documents. Schema is flexible per document.
{
"_id": "order_789",
"userId": "user_123",
"status": "shipped",
"items": [
{"productId": "prod_45", "name": "Keyboard", "qty": 1, "price": 79.99},
{"productId": "prod_46", "name": "Mouse", "qty": 2, "price": 29.99}
],
"shippingAddress": {
"street": "123 Main St",
"city": "New York"
}
}
Use when: Your data naturally fits a hierarchical, self-contained document. The order example above is a perfect fit — you almost always want the full order with its items, not a joined result.
Avoid when: You need to query across relationships frequently, or your schema is highly relational.
2. Key-Value Stores (Redis, DynamoDB, Riak)
The simplest model: a key maps to a value. Lightning-fast lookups.
# Redis: O(1) lookup by key
redis.set("session:abc123", json.dumps({"userId": "123", "role": "admin"}), ex=3600)
session = redis.get("session:abc123")
# DynamoDB: partition key + optional sort key
table.get_item(Key={"userId": "123", "orderId": "order_789"})
Use when: You need ultra-fast single-key lookups, session storage, caching, or counters.
Avoid when: You need complex queries, filtering, or joins.
3. Column-Family Stores (Cassandra, HBase, ScyllaDB)
Data is stored in column families, optimized for time-series, write-heavy workloads.
-- Cassandra: Schema designed around query patterns, not data normalization
CREATE TABLE sensor_readings (
device_id UUID,
timestamp TIMESTAMP,
temperature FLOAT,
humidity FLOAT,
PRIMARY KEY (device_id, timestamp) -- Partition by device, sort by time
) WITH CLUSTERING ORDER BY (timestamp DESC);
-- This query is O(1) — it maps directly to the storage layout
SELECT * FROM sensor_readings WHERE device_id = ? LIMIT 100;
Use when: You have massive write volumes, time-series data, or IoT workloads. Cassandra can handle millions of writes per second.
Avoid when: You need complex queries that don't match your partition key, or ACID transactions.
4. Graph Databases (Neo4j, Amazon Neptune)
Data is modeled as nodes and edges. Relationships are first-class citizens.
-- Neo4j: Find all friends of Alice who also like "Distributed Systems"
MATCH (alice:User {name: "Alice"})-[:FRIENDS_WITH]->(friend:User)
WHERE (friend)-[:LIKES]->(:Topic {name: "Distributed Systems"})
RETURN friend.name
Use when: Your domain is fundamentally relational in a graph sense — social networks, recommendation engines, fraud detection, knowledge graphs.
Avoid when: Most other use cases. Graph databases are powerful but operationally complex.
PostgreSQL — Why It Often Wins Even Against NoSQL
PostgreSQL has quietly absorbed many NoSQL use cases:
-- JSONB column — document storage with SQL query capabilities
CREATE TABLE events (
id UUID PRIMARY KEY,
type VARCHAR(50),
payload JSONB,
created_at TIMESTAMPTZ DEFAULT NOW()
);
-- GIN index on JSONB — fast document queries
CREATE INDEX idx_events_payload ON events USING GIN (payload);
-- Query inside JSON
SELECT * FROM events
WHERE payload->>'userId' = '123'
AND type = 'purchase';
-- Full-text search (no Elasticsearch for basic cases)
CREATE INDEX idx_products_search ON products USING GIN (to_tsvector('english', name || ' ' || description));
SELECT * FROM products
WHERE to_tsvector('english', name || ' ' || description) @@ to_tsquery('mechanical & keyboard');
-- Time-series with partitioning (comparable to Cassandra for many workloads)
CREATE TABLE metrics (
time TIMESTAMPTZ NOT NULL,
device_id UUID NOT NULL,
value FLOAT
) PARTITION BY RANGE (time);
Before adding a new database to your stack, check if PostgreSQL already handles it. Adding a database means another system to operate, monitor, backup, and train your team on.
Indexing — The Most Impactful Optimization Most Teams Underuse
A missing index is almost always the first cause of a slow query. An unnecessary index slows down writes.
-- EXPLAIN ANALYZE: your best friend for query performance
EXPLAIN ANALYZE
SELECT * FROM orders
WHERE user_id = '123'
AND status = 'pending'
ORDER BY created_at DESC;
-- If you see "Seq Scan" on a large table, you're missing an index
-- Seq Scan (cost=0.00..45000.00 rows=5 width=200) -- ❌ scanning every row
-- Add a composite index matching your query
CREATE INDEX idx_orders_user_status_created
ON orders (user_id, status, created_at DESC);
-- Now: Index Scan — fast
-- Index Scan using idx_orders_user_status_created (cost=0.42..8.50 rows=5) -- ✅
Composite index rule: Column order matters. Put equality conditions first (user_id, status), range/sort columns last (created_at).
The Decision Framework
| Your primary need | Consider |
|---|---|
| ACID transactions, complex queries, relational data | PostgreSQL / MySQL |
| Document storage, flexible schema, hierarchical data | MongoDB (or PostgreSQL JSONB) |
| Ultra-fast key lookups, sessions, caching | Redis |
| Massive write throughput, time-series, IoT | Cassandra / ScyllaDB (or Timescale on PG) |
| Full-text search, faceted search | Elasticsearch / OpenSearch (or PG full-text for simpler cases) |
| Graph traversals, social networks | Neo4j / Neptune |
| Analytical queries over large datasets | BigQuery / Redshift / ClickHouse |
Polyglot Persistence — When Multiple Databases Make Sense
Large systems often use multiple databases, each for a specific purpose:
User Service → PostgreSQL (relational, ACID, user accounts/billing)
Product Catalog → Elasticsearch (full-text search, faceted filtering)
Session Store → Redis (fast key-value, TTL-based expiry)
Activity Feed → Cassandra (high write throughput, time-ordered)
Recommendations → Neo4j (graph traversals)
Analytics → BigQuery (analytical, columnar, petabyte-scale)
The warning: Each database you add is a system you must operate. Start with the minimum. Introduce a new store only when you have a concrete, measurable pain point that your current database can't address.
Key Takeaways
- ACID transactions are invaluable — don't give them up unless you have a compelling reason
- CAP theorem is a useful frame: in a partition, choose consistency (banking) or availability (social feeds) based on your domain
- NoSQL solves specific problems — document stores, column families, key-value, graphs are each optimized for different access patterns
- PostgreSQL can handle more than you think — JSONB, full-text search, and partitioning cover many NoSQL use cases
- Indexing is the highest-ROI database optimization — understand your query patterns before adding hardware
- Polyglot persistence is real in large systems — but each database added is operational overhead
What's the most painful database migration you've been through — either choosing the wrong one initially, or scaling beyond what it could handle?
Next in the series → Post 05: When to Stop Calling APIs and Start Publishing Events
You've got your data store figured out. The next scaling inflection point is usually: synchronous calls don't compose well at scale.