Scaling: Before You Buy More Servers, Read This
Series: Backend Engineering Fundamentals · Post 06 of 07 Level: Beginner-friendly · Read time: ~8 min
"We need to scale" is one of the most expensive sentences in engineering.
It triggers infrastructure discussions, migration projects, and architectural rewrites — often before anyone has looked at whether the current system is actually running at capacity.
Before scaling your infrastructure, understand what you're actually scaling for. Most systems that feel slow are bottlenecked by code problems (N+1 queries, missing indexes, synchronous calls that should be async) — not infrastructure capacity. Scaling a slow system gives you a more expensive slow system.
This post covers the actual mechanics of scaling, the tradeoffs between approaches, and how to think about it before opening a cloud console.
Vertical vs Horizontal Scaling
Vertical scaling (Scale Up): Add more resources to existing servers — bigger CPU, more RAM, faster disk.
Horizontal scaling (Scale Out): Add more servers and distribute the load across them.
Vertical Scaling Horizontal Scaling
[Server: 8 CPU, 32GB] → [Server: 4 CPU, 16GB] ×3
↓ ↓
[Server: 32 CPU, 128GB] [Server: 4 CPU, 16GB] ×10
(one big machine) (many smaller machines)
| Vertical | Horizontal | |
|---|---|---|
| Simplicity | Simple — no code changes | Complex — requires stateless design |
| Cost | Expensive at high end (premium hardware) | Cheaper per unit at scale |
| Failure impact | Single point of failure | Redundant — one server failure is minor |
| Ceiling | Hard limit on available hardware | Theoretically unlimited |
| Database | Works well (most DBs scale vertically first) | Sharding required for DBs |
In practice: Start with vertical scaling. It's simpler, faster, and often sufficient. Switch to horizontal when you hit the vertical ceiling or need high availability.
The Stateless Requirement for Horizontal Scaling
Horizontal scaling only works if your application is stateless — each request can be handled by any server, with no local state that makes one server "special."
❌ Stateful — Can't Scale Horizontally
Server 1: User session in memory → [Request for user A] works
Server 2: No session for user A → [Request for user A] fails
✅ Stateless — Scales Horizontally
Server 1: No local state → reads session from Redis
Server 2: No local state → reads session from Redis
Server 3: No local state → reads session from Redis
Any server can handle any request.
Load balancer distributes freely.
The rule: Move all state out of your application servers and into shared storage (Redis for sessions, S3 for files, your database for persistent data). Your servers should be interchangeable.
# ❌ Stateful — in-memory session
app.sessions[user_id] = {"cart": items} # Lives on one server only
# ✅ Stateless — session in Redis
redis.setex(f"session:{session_id}", 3600, json.dumps({"cart": items}))
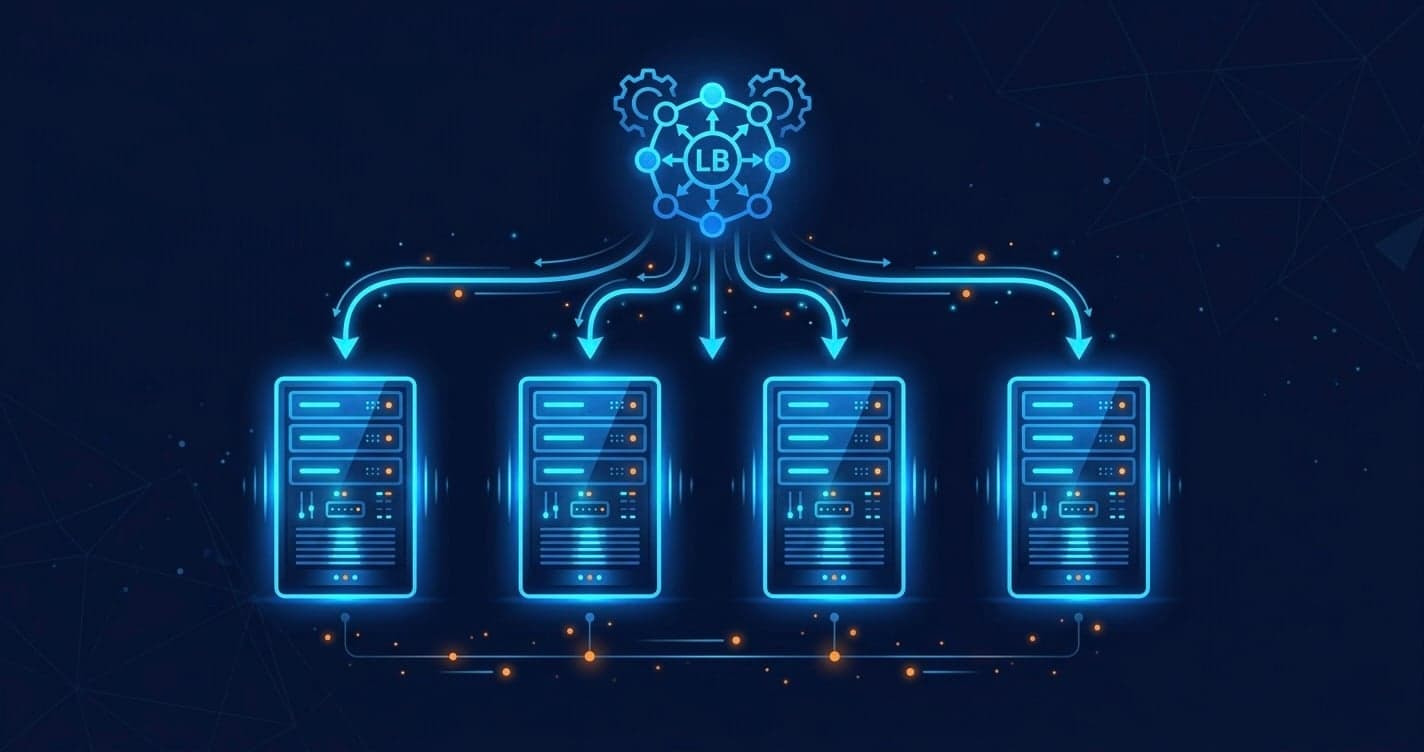
Load Balancers — The Front Door to Your Scaled System
A load balancer distributes incoming requests across your pool of servers.
Internet
↓
[Load Balancer]
├── Server 1
├── Server 2
└── Server 3
Load balancing algorithms:
| Algorithm | How it works | Use when |
|---|---|---|
| Round Robin | Requests distributed in sequence (1→2→3→1→2→3) | Servers have equal capacity and similar request costs |
| Least Connections | Routes to server with fewest active connections | Requests have variable processing time |
| IP Hash | Routes same client IP to same server | You need session stickiness and can't use a shared session store |
| Weighted | Servers get traffic proportional to weight | Servers have different capacities |
| Random | Random server selection | Surprisingly effective at scale; simple to implement |
Layer 4 vs Layer 7:
- L4 (TCP/UDP): Routes based on IP address and port. Extremely fast, no content inspection. AWS NLB, HAProxy in TCP mode.
- L7 (HTTP): Routes based on HTTP content (URL, headers, cookies). More flexible — route
/apito one pool,/staticto another. AWS ALB, NGINX, Traefik.
# NGINX: Layer 7 load balancing with upstream pools
upstream api_servers {
least_conn; # Least connections algorithm
server app1.internal:8080 weight=3;
server app2.internal:8080 weight=3;
server app3.internal:8080 weight=1; # Lower weight = less traffic
keepalive 32; # Connection pool to upstream servers
}
upstream static_servers {
server static1.internal:8080;
server static2.internal:8080;
}
server {
location /api/ {
proxy_pass http://api_servers;
}
location /static/ {
proxy_pass http://static_servers;
}
}
Database Scaling — Where It Gets Hard
Application servers are stateless and easy to scale. Databases are stateful and hard.
Read Replicas — The First Move
Most applications are read-heavy. Add read replicas and route SELECT queries there.
Primary DB (writes)
↓ replication
Replica 1 (reads)
Replica 2 (reads)
Replica 3 (reads)
Application:
- INSERT / UPDATE / DELETE → Primary
- SELECT → Random replica
# Connection routing example
def get_db_connection(read_only: bool = False):
if read_only:
return random.choice(replica_connections)
return primary_connection
Limitation: Replication lag. Replicas are slightly behind the primary (usually milliseconds, but can grow under load). Don't read from a replica immediately after a write if you need the result.
Connection Pooling — Before You Add Replicas
Before adding replicas, make sure you're not wasting connections. Databases have a hard limit on concurrent connections. Without pooling, a spike in traffic can exhaust connections instantly.
# SQLAlchemy connection pool
engine = create_engine(
DATABASE_URL,
pool_size=20, # Normal pool size
max_overflow=30, # Extra connections under load
pool_timeout=30, # Wait up to 30s for a connection before error
pool_recycle=3600 # Recycle connections after 1 hour
)
For PostgreSQL at scale, use PgBouncer — a lightweight connection pooler that sits between your app and the database, multiplexing thousands of application connections onto a smaller number of actual DB connections.
Sharding — The Last Resort
When a single primary + replicas isn't enough, you shard: split your data across multiple databases.
User IDs 1–1M → Database Shard 1
User IDs 1M–2M → Database Shard 2
User IDs 2M–3M → Database Shard 3
The costs are real:
- Cross-shard queries (JOINs across shards) become application logic
- Transactions across shards require distributed transaction handling
- Resharding (when a shard gets too large) is painful
- Every query needs shard-routing logic
Sharding adds enormous operational complexity. Exhaust all other options first: indexing, query optimization, read replicas, caching, connection pooling, vertical scaling.
Auto-Scaling — Elasticity, Not Magic
Auto-scaling adds or removes servers based on load. This is valuable for variable traffic patterns (traffic spikes on product launches, Black Friday, etc.).
# AWS Auto Scaling Group (simplified)
AutoScalingGroup:
MinSize: 2 # Always at least 2 servers
MaxSize: 20 # Never exceed 20 servers
DesiredCapacity: 4 # Start with 4
ScalingPolicy:
ScaleOut:
Trigger: CPUUtilization > 70% for 2 minutes
Action: Add 2 instances
ScaleIn:
Trigger: CPUUtilization < 30% for 10 minutes
Action: Remove 1 instance
Auto-scaling pitfalls:
Cold start time: If spinning up a new instance takes 3 minutes, it won't help with a traffic spike that peaks in 1 minute. Pre-warm with a higher minimum capacity.
Scale-in aggressiveness: Removing servers too aggressively causes thrashing (scale up, scale down, scale up again). Add a cooldown period.
Database doesn't scale automatically: Auto-scaling your app tier is useless if your database becomes the bottleneck. Ensure your DB can handle the connection surge from new instances.
Stateful sessions: If you forgot the stateless requirement, auto-scaling will cause session loss when a server is removed.
CDN for Static Assets — The Easiest Win
Before spending time on application scaling, ask: how much of your traffic is serving static files (JS, CSS, images)?
A CDN serves these from edge locations close to users, eliminating the load from your application servers entirely.
Without CDN:
User (Tokyo) → [Internet] → App Server (US East) → serve image (300ms)
With CDN:
User (Tokyo) → CDN Edge (Tokyo) → serve cached image (8ms)
This also reduces bandwidth costs, since CDN egress is typically cheaper than cloud server egress.
What to cache on CDN:
- All static assets with content-hash filenames (infinite TTL, cache-busted on deploy)
- API responses that are public and change infrequently (product catalog, pricing)
- Rendered HTML pages for anonymous users (massive scale lever for content sites)
Scaling Checklist — Before Adding Servers
Run through this before any infrastructure change:
- Are queries using indexes? (
EXPLAIN ANALYZEyour slow queries) - Is there N+1 query behavior in the application?
- Is connection pooling configured? (PgBouncer, HikariCP, SQLAlchemy pool)
- Are static assets served via CDN?
- Is read traffic separated to replicas?
- Are expensive computations cached?
- Are long-running operations async (queues) instead of blocking request threads?
- Is the application stateless (sessions in Redis, files in S3)?
Tick all of these before scaling horizontally. You'll likely find the bottleneck isn't what you thought.
Key Takeaways
- Scale vertically first — it's simpler and often enough
- Stateless design is the prerequisite for horizontal scaling — move all state to shared storage
- Load balancers distribute traffic; Layer 7 gives you routing flexibility
- Read replicas are the first database scaling move — they solve most read-heavy bottlenecks
- Connection pooling (PgBouncer) often eliminates "database can't scale" problems cheaply
- Sharding is a last resort — the complexity cost is real
- CDN and query optimization have better ROI than new servers in most systems
- Profile first. Most slow systems are code problems, not infrastructure problems.
What bottleneck surprised you most when your system first started struggling under load — was it what you expected?
Next in the series → Post 07: You Can't Manage What You Can't See — The Three Pillars of Observability
You've built and scaled your system. Now: how do you know it's working?